
基于 Babel 对 JS 代码进行混淆与还原操作的网站 JS 代码混淆与还原 (wenhao.cn)
还原前言
AST 仅仅只是静态分析,但可以将还原出来的代码替换原来的代码,以便更好的动态分析找出相关点。在还原时,并不是所有的代码都能还原成一眼就识破代码执行逻辑的,ast 也并非万能,如果你拥有强大的 js 逆向能力,有时候动态调试甚至比 AST 静态分析来的事半功倍。
还原不出最原始的代码
标识符是可以随便定义的,只要变量不冲突,我可以随意定义,那么就已经决定我们还原不出源代码的变量名,所以能还原的只有一些花指令,使其代码变好看,方便调试。
还原也不是万能的
混淆的方式有很多,与之对应还原的方式也有很多,上面那套混淆的还原可能只针对那一套混淆的代码,如果拿另一份混淆过的代码,然后执行这个还原程序的话,那程序多半有可能报错。所以绝对没有万能的还原代码,所有的还原程序,都需要针对不同的混淆手段来进行处理的。
我只是将我所遇到的混淆手段整合到一套代码上,而非所有的混淆手段都能进行还原处理的。
同时也别过于追求还原,因为还原很容易破坏原有代码,导致一些未知 bug。
如需要定制化还原,也可联系。(还是要说下,绝对无法还原出最原始代码)
例子
下文将会针对主流的一些混淆手段(至少是在我遇到的混淆中相对比较好还原的),并会附上对应代码供参考(不放置代码出处)。
接下来我将要演示一个混淆代码是如何还原的,这个例子是我第一次接触混淆的例子,也可以说是我玩的最溜的一次还原了,反正折腾了也有 4,5 来次。
贴上代码 git 地址 js-de-obfuscator/example/deobfuscator/cx
注:该 js 文件是通过工具JavaScript Obfuscator Tool进行混淆处理的。
分析 AST
首先一定一定要将混淆的代码解析成 AST 树结构,任何混淆的还原都是如此。首先简单随便看看代码,不难发现这些代码中都有'\x6a\x4b\x71\x4b'这样的十六进制编码字符,可以使用现成的工具,格式化便会限制编码前的结果,不过这边使用 ast 来进行操作
通过 AST 查看 node 节点,可以发现value正是我们想要的数据,但这里确显示的是extra.raw,实际上只需要遍历到相应的节点,然后 extra 属性给删除即可,同样的 Unicode 编码也是按上述方式显示。
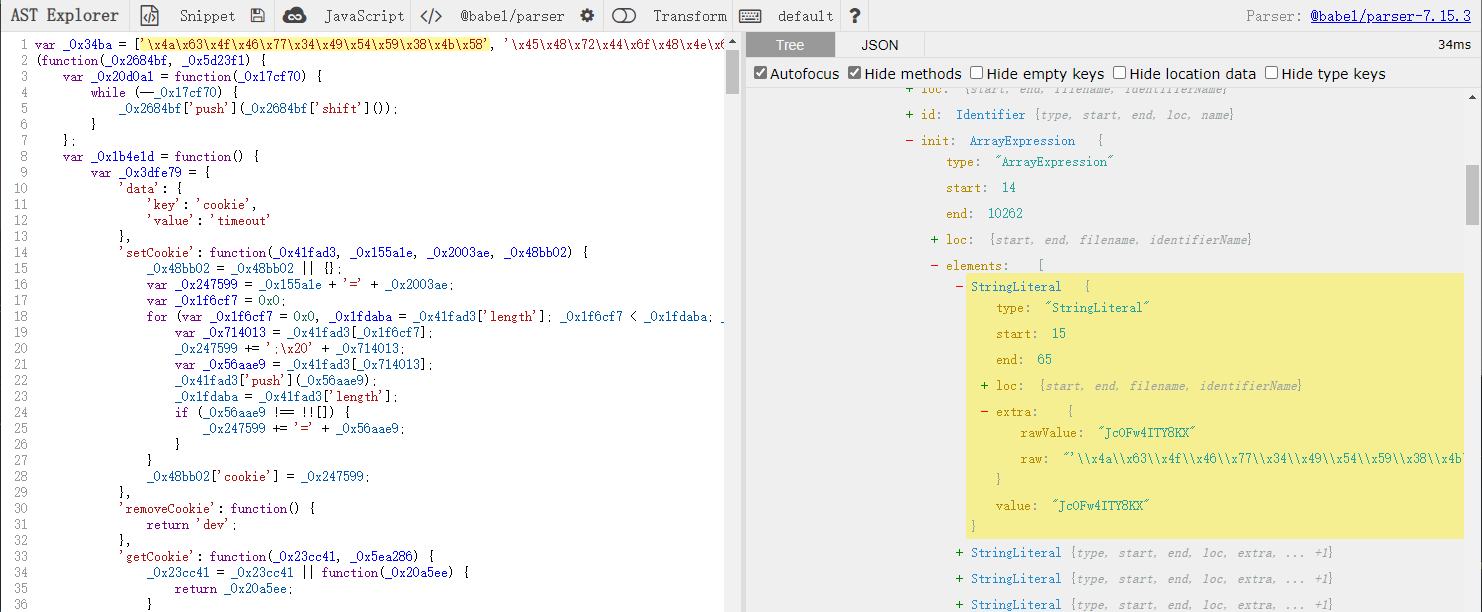
具体遍历的代码如下
// 将所有十六进制编码与Unicode编码转为正常字符
hexUnicodeToString() {
traverse(this.ast, {
StringLiteral(path) {
var curNode = path.node;
delete curNode.extra;
},
NumericLiteral(path) {
var curNode = path.node;
delete curNode.extra;
}
})
}
然后将遍历后处理过的代码与 demo.js 替换一下,方便接下来的还原处理。不过处理完还是有大部分未知的字符串需要解密,当然也有一些没处理过的代码。
找解密函数
如果你尝试过静态分析该代码,会发现一些参数都通过_0x3028 来调用,像这样
_0x3028['nfkbEK']
_0x3028('0x0', 'jKqK')
_0x3028('0x1', ')bls')
不过认真查看会发现像成员表达式MemberExpression语句_0x3028["nfkbEK"],但在第三条语句却定义函数_0x3028。其实是 js 的特性,比方说下面的代码就可以给函数添加一个自定义属性
let add = function (a, b) {
add['abc'] = 123
return a + b
}
console.log(add(1, 2))
console.log(add['abc'])
// 3
// 123
不过不影响,这里只是提一嘴,并不是代码的问题。而其中**_0x3028就是解密函数**,且遍历_0x3028调用表达式,且参数为两个的 CallExpression。
那么接下来就要着重查看前三个语句,因为这三条语句便是这套混淆的关键所在。
var _0x34ba = ["JcOFw4ITY8KX", "EHrDoHNfwrDCosO6Rkw=",...]
(function(_0x2684bf, _0x5d23f1) {
// 这里只是定义了一个数组乱序的函数,但是调用是在后面
var _0x20d0a1 = function(_0x17cf70) {
while (--_0x17cf70) {
_0x2684bf['push'](_0x2684bf['shift']());
}
};
var _0x1b4e1d = function() {
var _0x3dfe79 = {
'data': {
'key': 'cookie',
'value': 'timeout'
},
"setCookie": function (_0x41fad3, _0x155a1e, _0x2003ae, _0x48bb02) {
...
},
"removeCookie": function () {
return "dev";
},
"getCookie": function (_0x23cc41, _0x5ea286) {
_0x23cc41 = _0x23cc41 || function (_0x20a5ee) {
return _0x20a5ee;
};
// 在这里定义了一个花指令函数调用来调用
var _0x267892 = function (_0x51e60d, _0x57f223) {
_0x51e60d(++_0x57f223);
};
// 实际调用的地方
_0x267892(_0x20d0a1, _0x5d23f1);
return _0x1c1cc3 ? decodeURIComponent(_0x1c1cc3[1]) : undefined;
}
}
};
};
_0x1b4e1d();
}(_0x34ba, 296));
var _0x3028 = function (_0x2308a4, _0x573528) {
_0x2308a4 = _0x2308a4 - 0;
var _0x29a1e7 = _0x34ba[_0x2308a4];
// 省略百行代码...
return _0x29a1e7;
};
其中省略的代码没必要细读,因为后续都只将这三条语句写入到 node 内存中(eval),然后来调用。接下来分析每一个语句都是干嘛的。
大数组
基本 99%的混淆第一条语句都是一个大数组,存放这所有加密过的字符串,而我们要做的就是找到所有加密过的字符串,将其还原。
数组乱序
然后接着第二条语句一般都是自调用函数,将大数组与数组乱序数量作为参数,其中的作用是将数组进行乱序,也就是上面代码中加亮的地方,但这里只是定义了一个函数_0x20d0a1,而实际调用的地方 _0x1b4e1d 中_0x3dfe79.getCookie中调用的,上述代码中有注释。如果你是正常一步步分析还真不一定的分析的出来,这就是混淆恶心的地方。
不吹混淆了,总之只要知道第二条语句是用作数组乱序,而具体无论怎么混淆,我们都可以通过 eval 来调用一遍,详看后文代码。
解密函数
第三条语句就是加密函数,实际上就是传入大数组的索引,然后返回数组对应的成员,只是这边将其封装成函数,相当于原本 _0x34ba[0] 变为_0x3028("0x0", "jKqK") 形式来获取原本的字符串(这里只是举例,实际还涉及到第二个参数)。
还原字符串
上面说了那么多,实际上具体混淆逻辑其实根本没必要去理解,像传入的第二个参数做了啥根本无需了解,因为我们最终的目的是将 _0x3028("0x0", "jKqK")转为原本字符串,然后替换的当前节点的。所有只需要遍历到_0x3028("0x0", "jKqK"),然后执行一遍解密函数得到解密后的结果,然后替换即可。所以如何执行解密函数便是重点了。
将解密函数添加到内存中
首先要将三条语句运行一遍,js 中要在运行时运行字符串的代码,就可以使用 eval,但 eval 有作用域的问题,eval 运行的代码作用范围都是局部的,如果脱离当前作用域,eval 运行的代码就相当于无效了,所有可以使用window.eval或global.eval,将其写入置全局作用域下,由于这里是 node 环境,便用global.eval。
截取前三条语句,使用 eval 写入内存
// 拿到解密函数所在节点
let stringDecryptFuncAst = this.ast.program.body[2]
// 拿到解密函数的名字 也就是_0x3028
let DecryptFuncName = stringDecryptFuncAst.declarations[0].id.name
let newAst = parser.parse('')
newAst.program.body.push(this.ast.program.body[0])
newAst.program.body.push(this.ast.program.body[1])
newAst.program.body.push(stringDecryptFuncAst)
// 把这三部分的代码转为字符串,由于存在格式化检测,需要指定选项,来压缩代码
let stringDecryptFunc = generator(newAst, { compact: true }).code
// 将字符串形式的代码执行,这样就可以在 nodejs 中运行解密函数了
global.eval(stringDecryptFunc)
调用解密函数
这时候,就可以使用_0x3028("0x0", "jKqK") 来输出解密后的结果,不过要一个个手动输入还是太麻烦了,完全可以找到_0x3028调用的所有地方,然后判断是否为调用表达式 CallExpression,然后使用eval('_0x3028("0x0", "jKqK")') 获取解密结果。这边就举一个遍历的例子。
traverse(this.ast, {
VariableDeclarator(path) {
// 当变量名与解密函数名相同
if (path.node.id.name == DecryptFuncName) {
let binding = path.scope.getBinding(DecryptFuncName)
// 通过referencePaths可以获取所有引用的地方
binding &&
binding.referencePaths.map((p) => {
// 判断父节点是调用表达式,且参数为两个
if (p.parentPath.isCallExpression()) {
// 输出参数与解密后的结果
let args = p.parentPath.node.arguments.map((a) => a.value).join(' ')
let str = eval(p.parentPath.toString())
console.log(args, str)
p.parentPath.replaceWith(t.stringLiteral(str))
}
})
}
},
})
在混淆的时候就提及到 binding 可以获取当前变量的作用域,而binding.referencePaths就可以获取到所有调用的地方,那么只需要判断是否为调用表达式,且参数是两个的情况下,然后通过 eval 执行一遍整个节点,也就是eval('_0x3028("0x0", "jKqK")'),然后通过 replaceWith,替换节点即可。传入的参数与加密后的结果大致展示如下,可自行运行一遍程序中decStringArr()
0x0 jKqK PdAlB
0x1 )bls jtvLV
0x2 M10H SjQMk
0x3 2Q@E length
0x4 [YLR length
0x5 QvlS charCodeAt
0x6 YvHw IrwYd
0x7 iLkl ClOby
0x8 DSlT console
...
两者代码对比
原先代码与处理后的代码对比(部分)
var _0x505b30 = (function () {
if (_0x3028('0x0', 'jKqK') !== _0x3028('0x1', ')bls')) {
var _0x104ede = !![]
return function (_0x3d32a2, _0x35fd15) {
if ('bKNqX' === _0x3028('0x2', 'M10H')) {
var _0x46992c,
_0x1efd4e = 0,
_0x5cae2b = d(f)
if (0 === _0xb2c58f[_0x3028('0x3', '2Q@E')]) return _0x1efd4e
for (_0x46992c = 0; _0x46992c < _0xb2c58f[_0x3028('0x4', '[YLR')]; _0x46992c++)
(_0x1efd4e = (_0x1efd4e << (_0x5cae2b ? 5 : 16)) - _0x1efd4e + _0xb2c58f[_0x3028('0x5', 'QvlS')](_0x46992c)), (_0x1efd4e = _0x5cae2b ? _0x1efd4e : ~_0x1efd4e)
return 2147483647 & _0x1efd4e
} else {
var _0x45a8ce = _0x104ede
? function () {
if (_0x3028('0x6', 'YvHw') === _0x3028('0x7', 'iLkl')) {
that[_0x3028('0x8', 'DSlT')]['log'] = func
that[_0x3028('0x9', 'YW6h')][_0x3028('0xa', '&12i')] = func
that[_0x3028('0xb', '1jb4')]['debug'] = func
that[_0x3028('0xc', 'k9U[')][_0x3028('0xd', 'nUsA')] = func
that[_0x3028('0xe', ')bls')][_0x3028('0xf', 'PZDB')] = func
that['console'][_0x3028('0x10', 'r8Qx')] = func
that[_0x3028('0x11', 'AIMj')][_0x3028('0x12', '[YLR')] = func
} else {
if (_0x35fd15) {
if (_0x3028('0x13', 'r8Qx') !== _0x3028('0x14', 'YLF%')) {
var _0x1fa1e3 = _0x35fd15[_0x3028('0x15', 'sLdn')](_0x3d32a2, arguments)
_0x35fd15 = null
return _0x1fa1e3
} else {
_0x142a1e()
}
}
}
}
: function () {}
_0x104ede = ![]
return _0x45a8ce
}
}
} else {
;(function () {
return ![]
}
[_0x3028('0x16', 'Yp5j')](_0x3028('0x17', ']R4I') + _0x3028('0x18', 'M10H'))
[_0x3028('0x19', '%#u0')]('stateObject'))
}
})()
var _0x505b30 = (function () {
if ('PdAlB' !== 'jtvLV') {
var _0x104ede = !![]
return function (_0x3d32a2, _0x35fd15) {
if ('bKNqX' === 'SjQMk') {
var _0x46992c,
_0x1efd4e = 0,
_0x5cae2b = d(f)
if (0 === _0xb2c58f['length']) return _0x1efd4e
for (_0x46992c = 0; _0x46992c < _0xb2c58f['length']; _0x46992c++)
(_0x1efd4e = (_0x1efd4e << (_0x5cae2b ? 5 : 16)) - _0x1efd4e + _0xb2c58f['charCodeAt'](_0x46992c)), (_0x1efd4e = _0x5cae2b ? _0x1efd4e : ~_0x1efd4e)
return 2147483647 & _0x1efd4e
} else {
var _0x45a8ce = _0x104ede
? function () {
if ('IrwYd' === 'ClOby') {
that['console']['log'] = func
that['console']['warn'] = func
that['console']['debug'] = func
that['console']['info'] = func
that['console']['error'] = func
that['console']['exception'] = func
that['console']['trace'] = func
} else {
if (_0x35fd15) {
if ('WuEjf' !== 'qpuuN') {
var _0x1fa1e3 = _0x35fd15['apply'](_0x3d32a2, arguments)
_0x35fd15 = null
return _0x1fa1e3
} else {
_0x142a1e()
}
}
}
}
: function () {}
_0x104ede = ![]
return _0x45a8ce
}
}
} else {
;(function () {
return ![]
}
['constructor']('debu' + 'gger')
['apply']('stateObject'))
}
})()
可以发现处理过的代码至少无需动态调用出解密后的结果,并且像if ("PdAlB" !== "jtvLV")这种语句都可以直接一眼看出必定为 true,但混淆后if (_0x3028("0x0", "jKqK") !== _0x3028("0x1", ")bls"))却无法看出,这就是 AST 静态分析的优势所在。
删除混淆语句
在执行完字符串解密后,其实大数组与解密函数都已经用不到了,那么就可以通过 shift 将前三条语句给删除。
// 将源代码中的解密代码给移除
this.ast.program.body.shift()
this.ast.program.body.shift()
this.ast.program.body.shift()
但一般不推荐删除,因为我们有可能是需要将我们还原后的代码与网站内混淆过的代码进行替换,然后再进行动态调试分析,但如果删除了这三条混淆语句,有可能会导致代码执行出错。我之前习惯删除,但直到我遇到了一个网站。。。
最终整个完成的代码在类方法decStringArr
找解密函数优化
在上面的代码中有一段这样的代码
// 当变量名与解密函数名相同
if (path.node.id.name == DecryptFuncName) {
// ...
其中这里的 DecryptFuncName 对应的是解密函数的函数名_0x3028,是通过人为定义,同时载入的是前三条语句,万一解密函数在第四条语句,或者有多个解密函数的情况下,就需要去改动代码
// 拿到解密函数所在节点
let stringDecryptFuncAst = this.ast.program.body[2]
// 拿到解密函数的名字 也就是_0x3028
let DecryptFuncName = stringDecryptFuncAst.declarations[0].id.name
let newAst = parser.parse('')
newAst.program.body.push(this.ast.program.body[0])
newAst.program.body.push(this.ast.program.body[1])
newAst.program.body.push(stringDecryptFuncAst)
// 把这三部分的代码转为字符串,由于存在格式化检测,需要指定选项,来压缩代码
let stringDecryptFunc = generator(newAst, { compact: true }).code
无意间翻看代码的时候,灵光一现,解密函数调用的这么频繁,我直接把所有函数都遍历一遍,并将它们的引用referencePaths从高到低排序,不就知道那个是解密函数了吗,于是便有了findDecFunctionArr方法
findDecFunctionArr
一般而言,解密函数通常是在大数组与数组乱序后定义的,在上面代码中,可以看到是通过制定下标来定位解密函数 this.ast.program.body[2];,所以只要能截取到这个 2 即可,具体代码
/**
* 根据函数调用次数寻找到解密函数
*/
findDecFunction() {
let decFunctionArr = [];
let index = 0; // 定义解密函数所在语句下标
// 先遍历所有函数(作用域在Program),并根据引用次数来判断是否为解密函数
traverse(this.ast, {
Program(p) {
p.traverse({
'FunctionDeclaration|VariableDeclarator'(path) {
if (!(t.isFunctionDeclaration(path.node) || t.isFunctionExpression(path.node.init))) {
return;
}
let name = path.node.id.name;
let binding = path.scope.getBinding(name);
if (!binding) return;
// 调用超过100次多半就是解密函数,具体可根据实际情况来判断
if (binding.referencePaths.length > 100) {
decFunctionArr.push(name);
// 根据最后一个解密函数来定义解密函数所在语句下标
let binding = p.scope.getBinding(name);
if (!binding) return;
let parent = binding.path.findParent((_p) => _p.isFunctionDeclaration() || _p.isVariableDeclaration());
if (!parent) return;
let body = p.scope.block.body;
for (let i = 0; i < body.length; i++) {
const node = body[i];
if (node.start == parent.node.start) {
index = i + 1;
break;
}
}
// 遍历完当前节点,就不再往子节点遍历
path.skip();
}
},
});
},
});
let newAst = parser.parse('');
// 插入解密函数前的几条语句
newAst.program.body = this.ast.program.body.slice(0, index);
// 把这部分的代码转为字符串��,由于可能存在格式化检测,需要指定选项,来压缩代码
let code = generator(newAst, { compact: true }).code;
// 将字符串形式的代码执行,这样就可以在 nodejs 中运行解密函数了
global.eval(code);
this.decFunctionArr = decFunctionArr;
}
同时增加 decFunctionArr 属性,用于表示解密函数数组供 decStringArr 使用,就可以免去判断解密函数的步骤了。
优化还原后的代码
就此,还原后的代码基本就能静态分析出大概,接下来都是对这份代码进行细微的优化还原。
对象['属性'] 改为对象.属性
与混淆对象属性相反,但其实没必要,只是代码相对而言好看一点,影响不大。具体代码如下
changeObjectAccessMode() {
traverse(this.ast, {
MemberExpression(path) {
if (t.isStringLiteral(path.node.property)) {
let name = path.node.property.value
path.node.property = t.identifier(name)
path.node.computed = false
}
}
})
}
还原为 Boolean
在还原后的代码还存在!![]与 ![]或者是!0与!1,而这对应 js 中也就是true与false,所以也可以遍历这部分的代码,然后将其还原成 Boolean,像这种表达式就不细说了(有点类似 jsfuck),ast 结构自行分析。具体代码如下
traverseUnaryExpression() {
traverse(this.ast, {
UnaryExpression(path) {
if (path.node.operator !== '!') return // 避免判断成 void
// 判断第二个符号是不是!
if (t.isUnaryExpression(path.node.argument)) {
if (t.isArrayExpression(path.node.argument.argument)) { // !![]
if (path.node.argument.argument.elements.length == 0) {
path.replaceWith(t.booleanLiteral(true))
path.skip()
}
}
} else if (t.isArrayExpression(path.node.argument)) { // ![]
if (path.node.argument.elements.length == 0) {
path.replaceWith(t.booleanLiteral(false))
path.skip()
}
} else if (t.isNumericLiteral(path.node.argument)) { // !0 or !1
if (path.node.argument.value === 0) {
path.replaceWith(t.booleanLiteral(true))
} else if (path.node.argument.value === 1) {
path.replaceWith(t.booleanLiteral(false))
}
} else {
}
}
})
}
计算二项式字面量
还原后的代码中还存在["constructor"]("debu" + "gger")["call"]("action");这样的语句,其中debugger 特意给拆分成两部分,而这同样可以通过 ast 来进行还原成完整字符串,同样类似的 1 + 2 这种字面量 都可以合并。还原程序代码如下
traverseLiteral() {
traverse(this.ast, {
BinaryExpression(path) {
let { left, right } = path.node
// 判断左右两边是否为字面量
if (t.isLiteral(left) && t.isLiteral(right)) {
let { confident, value } = path.evaluate() // 计算二项式的值
confident && path.replaceWith(t.valueToNode(value))
path.skip()
}
}
});
}
其中 confident 表示是否为可计算,比如说一个变量 + 1,由于程序不知道这变量此时的值,所以就不可计算,confident 也就是为 false。
同时这个计算二项式字面量可以还原一些相对简单的混淆,比方说数字异或混淆 706526 ^ 706516计算为 10 就可以直接替换原节点。所以这步的遍历需要相对其他还原提前一些。
字符串和数值常量直接替换对应的变量引用地方
有些变量可能赋值过一次就不在进行改变,就如同常量,如下面代码。
let a = 100
console.log(a)
那么完全可以替换成console.log(100) ,最终输出的效果一样,但是前提是 a 只赋值过一次,也可以说 a 必须要是变量,否则这样还原是有可能导致原有执行结果失败,而通过 binding 就能查看变量 a 的赋值历史。
traverseStrNumValue() {
traverse(this.ast, {
'AssignmentExpression|VariableDeclarator'(path) {
let _name = null;
let _initValue = null;
if (path.isAssignmentExpression()) {
_name = path.node.left.name;
_initValue = path.node.right;
} else {
_name = path.node.id.name;
_initValue = path.node.init;
}
if (t.isStringLiteral(_initValue) || t.isNumericLiteral(_initValue)) {
let binding = path.scope.getBinding(_name);
if (binding && binding.constant && binding.constantViolations.length == 0) {
for (let i = 0; i < binding.referencePaths.length; i++) {
binding.referencePaths[i].replaceWith(_initValue);
}
}
}
},
});
}
移除无用变量与无用代码块
上面说了有些字符串与数值常量替换,针对是只赋值过一遍的变量,但还可能存在变量未使用过的情况,遇到这种情况,我们可以判断 constantViolations 成员是否为空,然后将其删除。
removeUnusedValue() {
traverse(this.ast, {
VariableDeclarator(path) {
const { id, init } = path.node;
if (!(t.isLiteral(init) || t.isObjectExpression(init))) return;
const binding = path.scope.getBinding(id.name);
if (!binding || binding.constantViolations.length > 0) return
if (binding.referencePaths.length > 0) return
path.remove();
},
FunctionDeclaration(path){
const binding = path.scope.getBinding(path.node.id.name);
if (!binding || binding.constantViolations.length > 0) return
if (binding.referencePaths.length > 0) return
path.remove();
}
});
}
同时还有一些无用代码块,比如
function test() {
if (true) {
return '123'
} else {
return Math.floor(10 * Math.random())
}
}
test()
第二条语句是绝对不会执行到的,那么就可以将其移除。虽然说代码编辑器会将其标暗,表示不会执行到,但在混淆中巴不得代码量少一下,所有还是有必要通过 AST 进行操作。
removeUnusedBlockStatement() {
traverse(this.ast, {
IfStatement(path) {
if (t.isBooleanLiteral(path.node.test)) {
let testValue = path.node.test.value
if (testValue === true) {
path.replaceInline(path.node.consequent)
} else if (testValue === false) {
path.replaceInline(path.node.alternate)
}
}
},
});
}
虽然说这种只针对 if 条件为 Boolean,如果条件为if(1===1)的情况也是可以,因为在前面还原中 计算二项式字面量,就已经将if(1===1) 替换成了 if(true),所以这里只需要判断isBooleanLiteral即可。最终还原后的结果会将 if 代码块去除,同时保留 BlockStatement,代码如下
function test() {
{
return "123";
}
}
test();
添加注释
有些关键的代码会隐藏在 debugger,setTimeout,setInterval 等,在调试的时候都需要额外注意下是否有关键代码,所以这时候就可以添加一个注释来进行添加一个标签如 TOLOOK 来进行定位。具体根据要指定的标识符来定位,下列代码做为演示,将会在这些地方添加注释 // TOLOOK
addComments() {
traverse(this.ast, {
DebuggerStatement(path) {
path.addComment('leading', ' TOLOOK', true);
},
CallExpression(path) {
if (!['setTimeout', 'setInterval'].includes(path.node.callee.name)) return;
path.addComment('leading', ' TOLOOK', true);
},
StringLiteral(path) {
if (path.node.value === 'debugger') {
path.addComment('leading', ' TOLOOK', true);
}
}
});
}
十六进制与 Unicode 编码转正常字符
在一开始还原的时候就调用过这个方法,不过这里要特意在说一遍,因为这套混淆十六进制是最后处理,也就是说我们一开始直接使用还原是没问题的,但如果加密的字符串中存在十六进制编码字符,而这步操作确实在解密字符串前的话,那么可能就有部分字符串还是以十六进制形式显示,所有把这个方法特意放到较后文的地方,同时这个方法也可以最后调用。
hexUnicodeToString() {
traverse(this.ast, {
StringLiteral(path) {
var curNode = path.node;
delete curNode.extra;
},
NumericLiteral(path) {
var curNode = path.node;
delete curNode.extra;
},
});
}
标识符优化
大部分的混淆标识符都为_0x123456 这种,但有些却很另类,比如 OOOO0o 这种,相比前面这种更容易看花眼,很容易看错代码,那么就可以将标识符都统一重命名一下。
renameIdentifier() {
let code = this.code
let newAst = parser.parse(code);
traverse(newAst, {
'Program|FunctionExpression|FunctionDeclaration'(path) {
path.traverse({
Identifier(p) {
path.scope.rename(p.node.name, path.scope.generateUidIdentifier('_0xabc').name);
}
})
}
});
this.ast = newAst;
}
但想知道源代码的标识符是根本不可能的,所以就无法通过代码语义来理解代码了。
不过还有一些可以特定的替换,比如 for i
for (var _0x1e5665 = 0, _0x3620b9 = this['JIyEgF']['length']; _0x1e5665 < _0x3620b9; _0x1e5665++) {
this['JIyEgF']['push'](Math['round'](Math['random']()))
_0x3620b9 = this['JIyEgF']['length']
}
像这种代码,就完全可以将_0x1e5665替换成i,不过对整体阅读影响基本不大。
其他还原手段
还有一些还原的手段就不细说了(这里例子中并未用到),比如说
- 形参改为实参
- 还原 switch 执行流程
- 处理对象花指令
- 处理 eval 代码
等等,总之你想咋优化都完全可以优化,但还原完的代码就不一定能看懂了。与解密字符串那个相比,如果搞不定字符串解密,那这些都是徒劳。
具体的实例可通过 源码例子 ��中查看对 AST 的操作。
运行还原后的代码
最终整个还原后的代码可以在newCode.js中查看,但到目前为止还没有测试还原后的代码到底能否正常运行,或者是替换节点导致语法错误,所有就需要将还原后的代码与混淆过的代码替换运行这样才能测试的出来。这里就不放具体执行过程了(因为真的懒得在处理这个 js 文件了。。。)
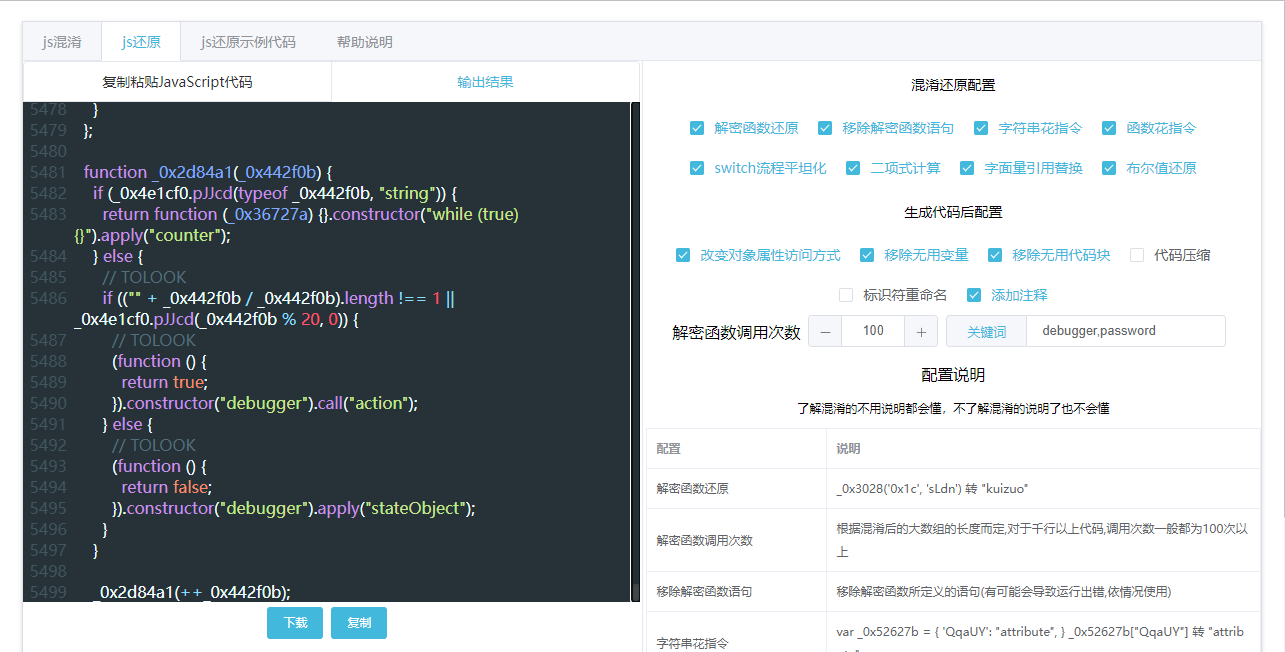
JS 混淆与还原的网站
针对上述还原操作其实还不够明显,于是就编写了一个在线对 JS 代码混淆与还原的网站(主要针对还原)– JS 代码混淆与还原 (wenhao.cn)
其实也就是对上述的还原代码进行封装成工具使用。