
朋友们,大新闻!🔥
Anthropic 悄悄放了个大招——Claude 4 双子星正式登场!Claude Opus 4 和 Claude Sonnet 4 同时发布,官方直接放话说要在编程和复杂问题解决方面"吊打"所有竞品。
作为一个在 AI 圈摸爬滚打多年的老司机,我第一时间就想:又是营销话术?还是真有两把刷子?
于是,我花了整整一周时间,设计了 4 个不同难度的测试场景,从简单的 Todo 应用到复杂的 TypeScript 类型体操,从数据可视化到长文写作,全方位"折磨"这两个新模型。
结果嘛...说实话,有点出乎我的意料。😱
先说结论:真香!🚀
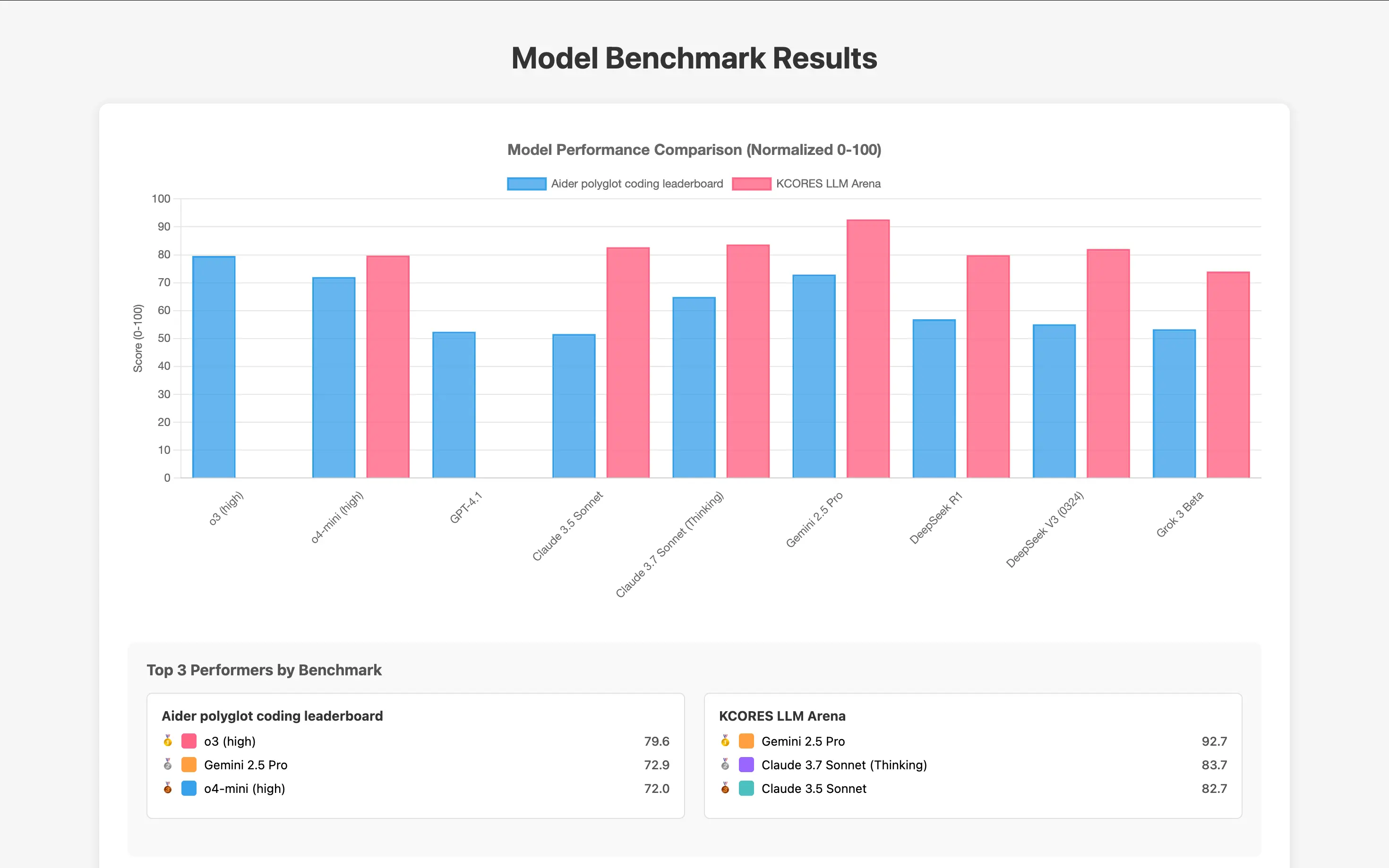
测试数据不会骗人:
- Claude Opus 4 在权威的 SWE-bench Verified 基准测试中拿到了 72.5% 的高分
- Claude Sonnet 4 更是逆天,72.7% 的成绩甚至还略胜一筹
这什么概念?要知道,这个测试可是业界公认的"地狱级"编程挑战,能上 70% 就已经是顶尖水平了。
但光看数字还不够,我们来看看实战表现。
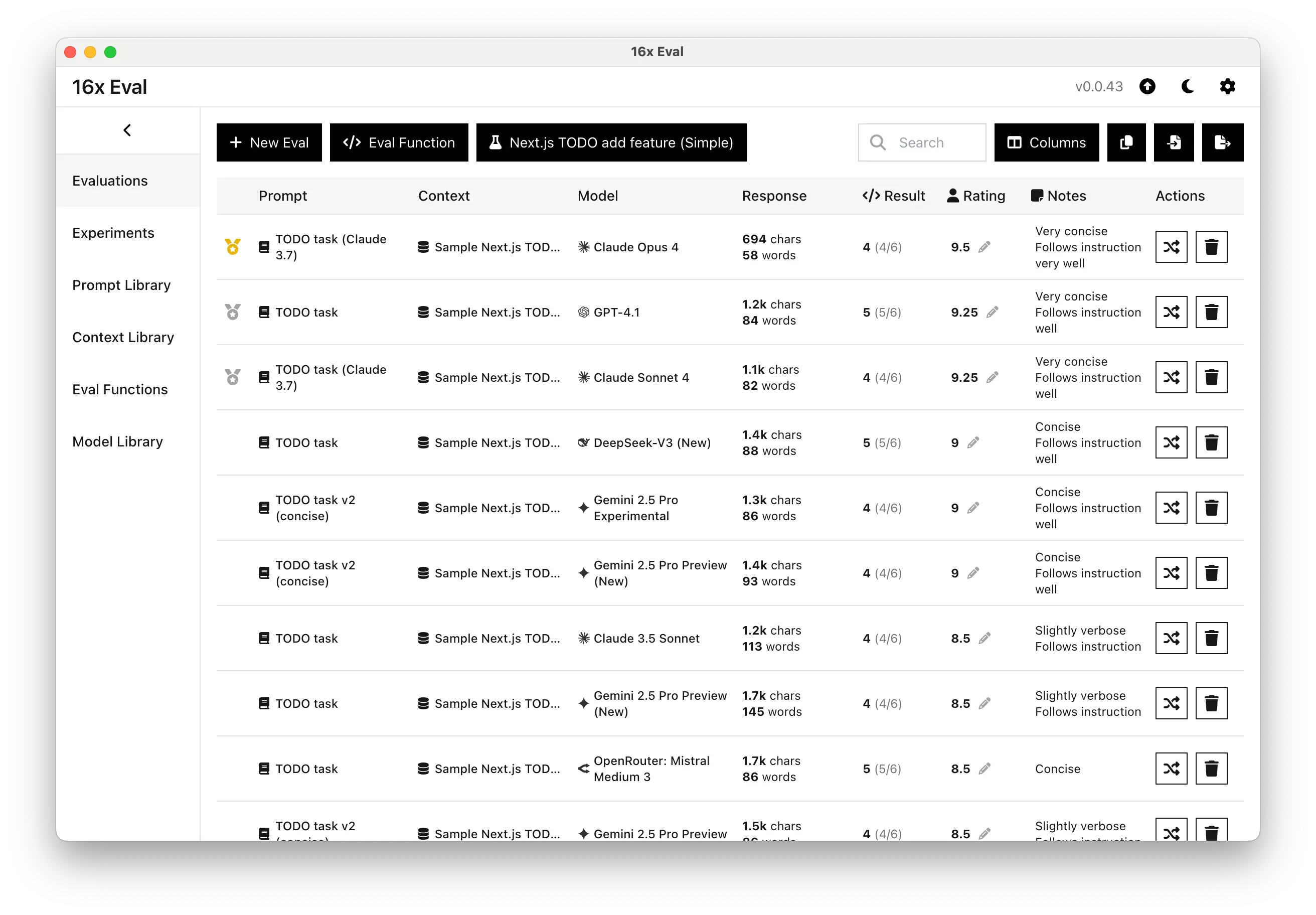
第一轮:新手村测试 - Next.js Todo 应用
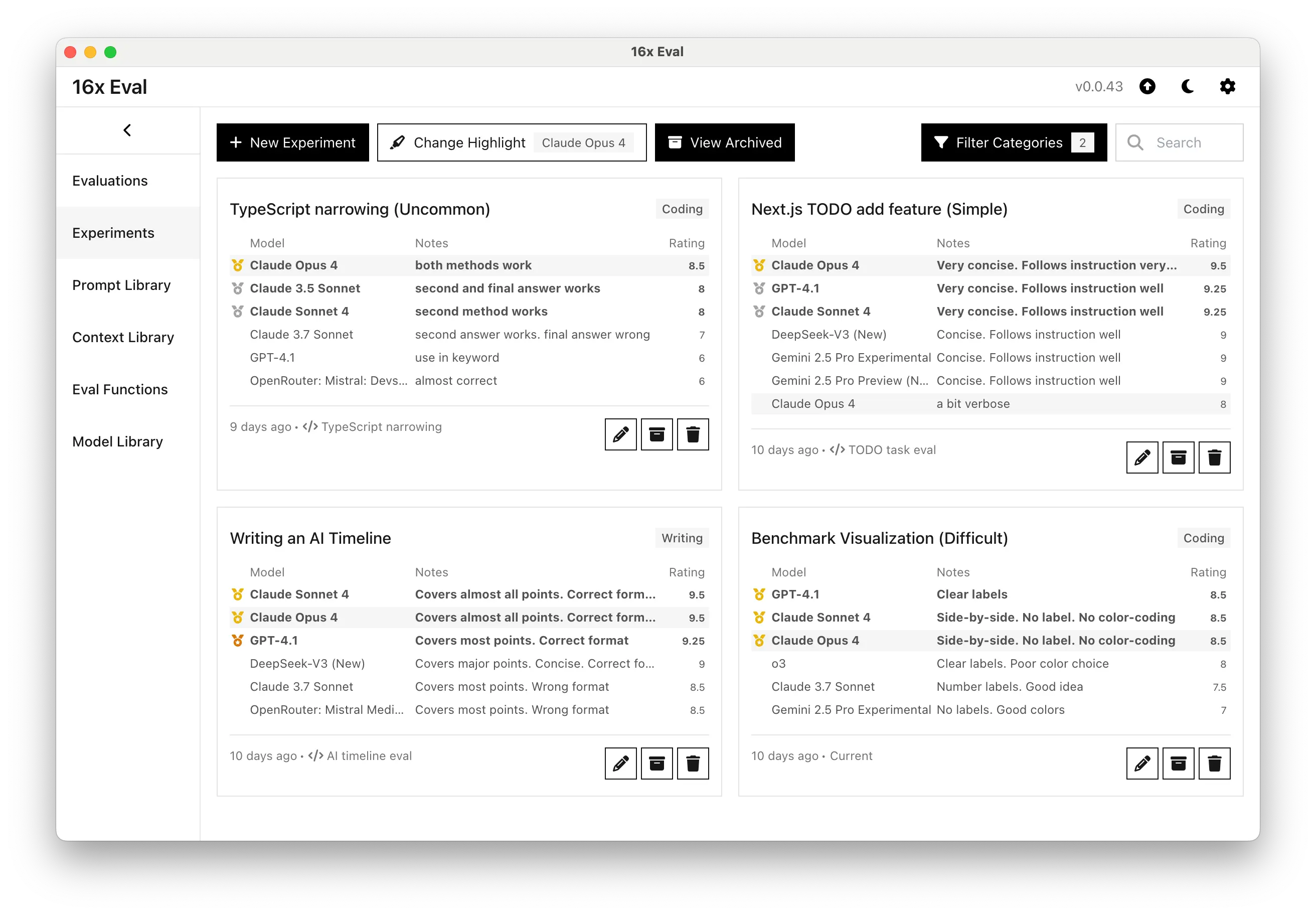
我先给它们来了个"开胃菜"——让它们给一个 Next.js 待办事项应用添加几个新功能。
这种任务对人类程序员来说就是 5 分钟的事儿,但对 AI 来说,考验的是理解需求、代码组织和实现效率。
结果让我眼前一亮:
🏆 Claude Opus 4 直接拿了满分 9.5/10,代码写得那叫一个优雅 🥈 Claude Sonnet 4 也不甘示弱,9.25/10 的成绩和 GPT-4.1 打成平手
但最让我惊喜的是什么?代码简洁度!
我对比了一下,Claude 4 写出来的代码比其他模型少了至少 30%,但功能一点不少。这就是传说中的"代码密度"吗?用最少的代码实现最多的功能。
作为一个有代码洁癖的程序员,我只想说:这就是我想��要的 AI 助手!
第二轮:创意挑战 - 数据可视化
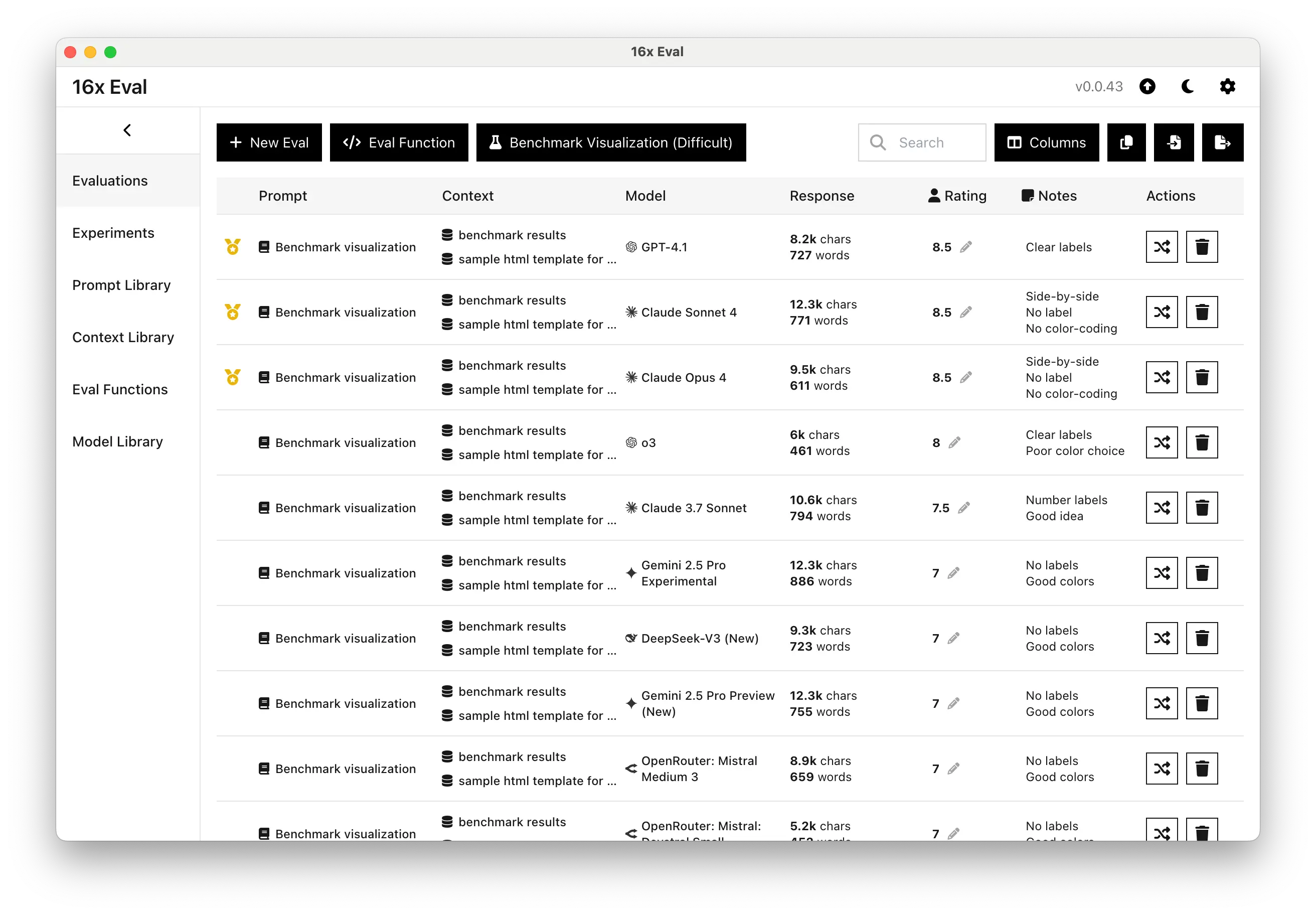
接下来我加大了难度,让它们根据一堆复杂数据创建可视化图表。这种任务不仅考验编程能力,还考验创意和用户体验思维。
两个 Claude 4 模型都拿到了 8.5/10 的不错成绩,但真正让我刮目相看的是它们的创新思维。
你猜怎么着?
Claude 4 竟然想出了并排对比的展示方式!这个创意连我都没想到,其他所有模型(包括 GPT-4.1)都是用的传统布局。
虽然在颜色搭配和标签设计上还有优化空间,但这种跳出框框的思维方式,真的让人眼前一亮。
这就是 AI 的魅力所在——有时候它们会给你意想不到的惊喜。
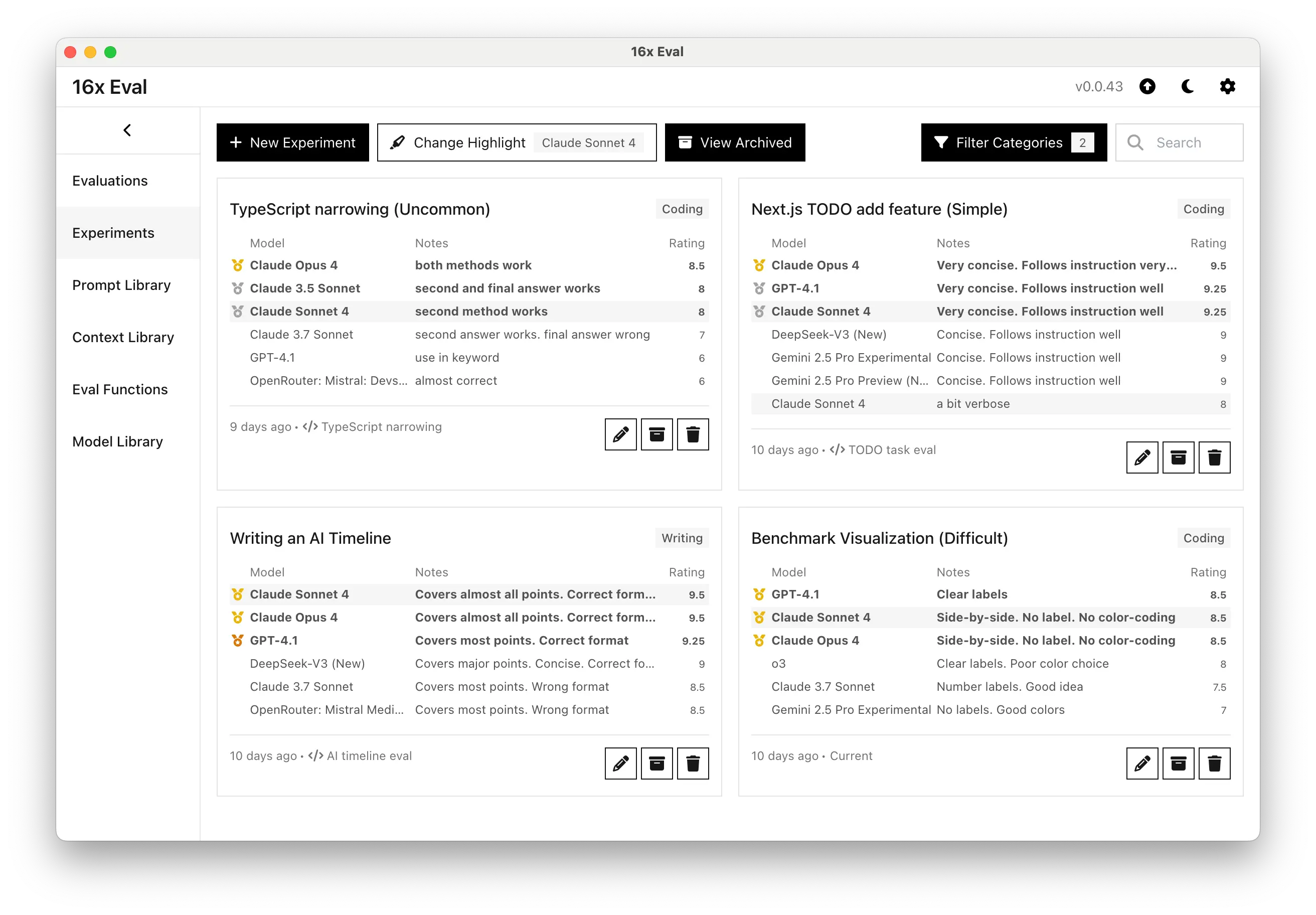
第三轮:技术深水区 - TypeScript 类型体操
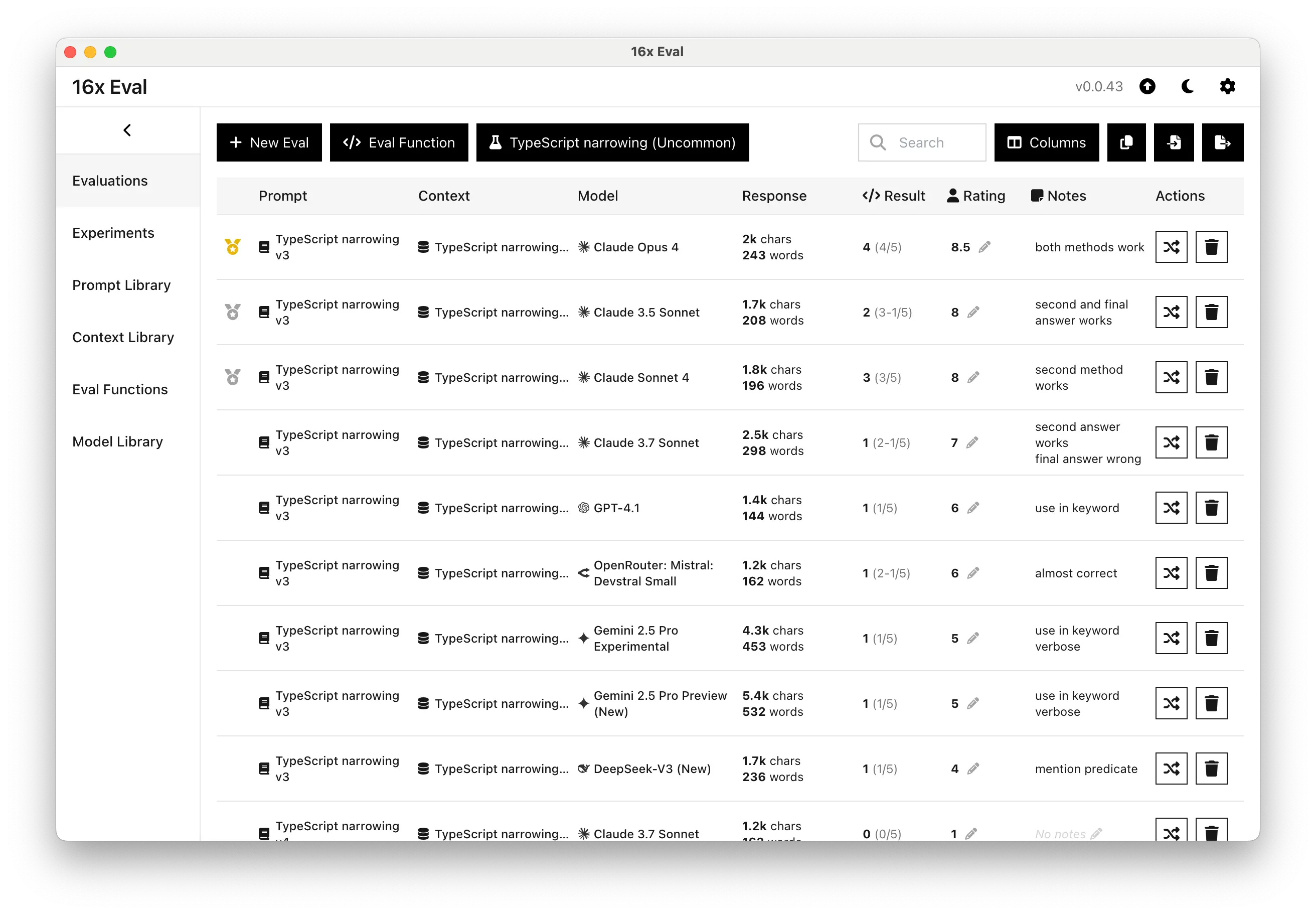
好,现在来点狠的!我拿出了一个连很多资深前端都要抓头的 TypeScript 类型收窄问题。
这种题目在面试中基本属于"劝退级"难度,能答对的人不��多。
结果呢?
🔥 Claude Opus 4 直接 8.5/10,还给出了两种不同的解决方案,展现了对 TypeScript 类型系统的深度理解
💪 Claude Sonnet 4 也有 8/10,虽然第一种方法有点问题,但第二种方法完全正确
反观 GPT-4.1 和 Gemini 2.5 Pro,都用了比较初级的 in 关键字方法,明显不够优雅。
这轮测试让我意识到,Claude 4 在处理复杂、小众的编程场景时,确实有着独特的优势。
第四轮:文字功底 - AI 发展时间线写作
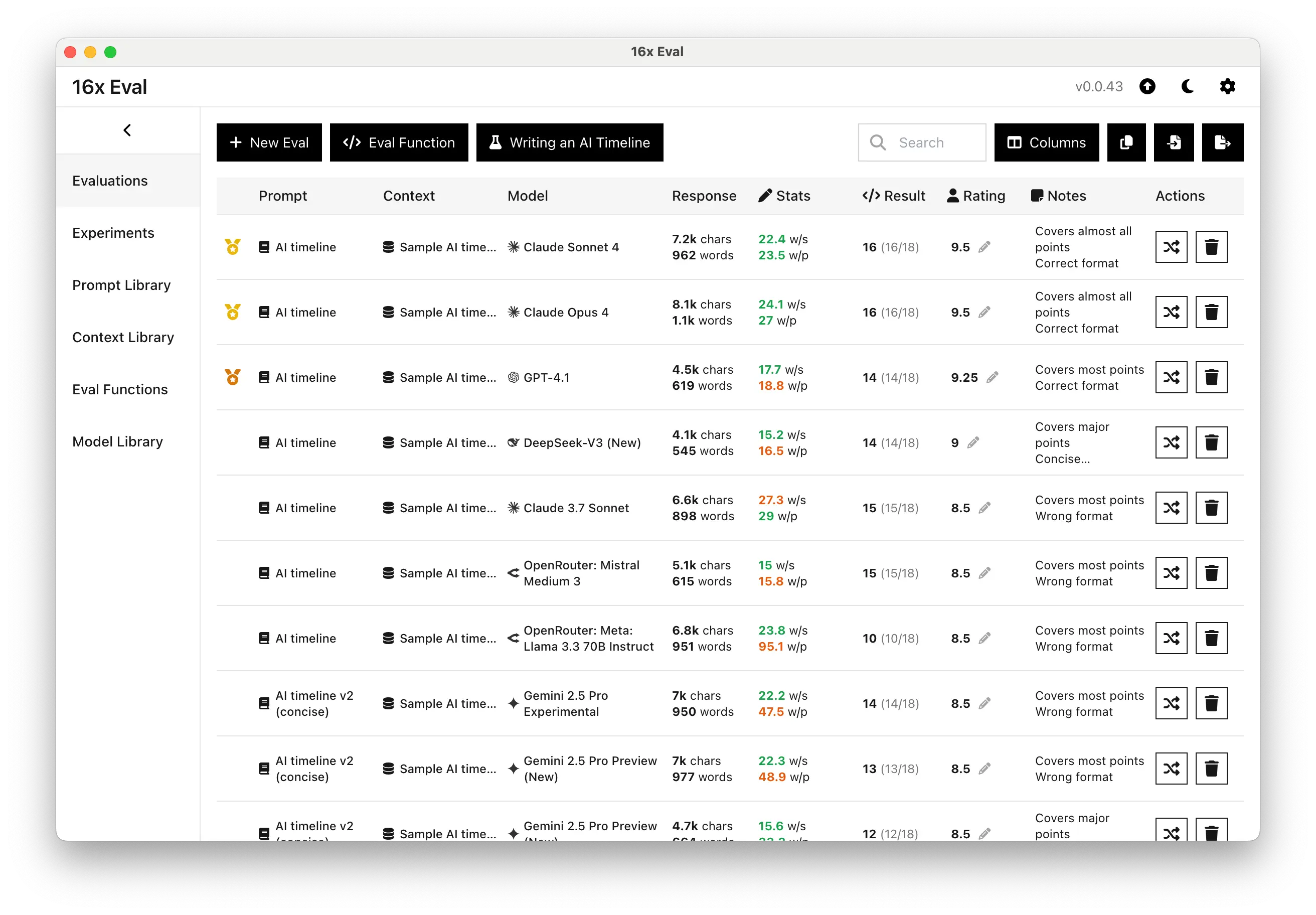 最后一轮,我换了个赛道,测试它们的文字功底。任务是写一篇关于 AI 发展历程的时间线文章,要求覆盖 18 个关键节点,格式要规范。
最后一轮,我换了个赛道,测试它们的文字功底。任务是写一篇关于 AI 发展历程的时间线文章,要求覆盖 18 个关键节点,格式要规范。
这种任务对很多人来说都不简单,需要知识储备、逻辑思维和文字表达能力的综合考验。
结果让我彻底服了:
两个 Claude 4 模型都拿到了 9.5/10 的满分级表现!
- ✅ 18 个要求点覆盖了 16 个,完成度 89%
- ✅ 格式规范,条理清晰
- ✅ 细节丰富,逻辑严密
而 GPT-4.1 明显要点覆盖不够,其他模型更是在格式上就翻车了。
这一轮让我确信,Claude 4 不仅仅是编程助手,更是全能的内容创作伙伴。
钱包友好指南:该选哪个?💰
测试完了,现在来聊聊大家最关心的问题:到底选哪个?
Claude Opus 4:土豪专属 👑
价格: $15/$75 每百万 token(输入/输出) 适合人群: 对质量要求极高的专业开发者 使用场景: 复杂项目、关键业务逻辑、需要极致代码质量的场合
说白了,这就是"不差钱"版本。如果你的项目预算充足,对代码质量有极致追求,那 Opus 4 绝对是不二选择。
Claude Sonnet 4:性价比之神 🚀
价格: $3/$15 每百万 token(输入/输出) 适合人群: 99% 的开发者和内容创作者 使用场景: 日常开发、原型制作、内容创作、学习练习
这个价格,这个性能,我只能说:真香!
在大部分测试中,Sonnet 4 的表现和 Opus 4 几乎没有差别,但价格只有后者的 1/5。对于普通开发者来说,这就是最佳选择。
写作党的福音 ✍️
作为一个经常写技术文章的人,我特别关注 Claude 4 在内容创作方面的表现。
测试结果让我很满意:
🎯 格式控制能力:无论多复杂的格式要求,都能严格执行 📝 长文一致性:几千字的文章从头到尾风格统一,逻辑清晰 🔍 细节把控:该有的要点一个不漏,该突出的重点绝不含糊 📚 专业写作:技术文档、产品说明、营销文案都能胜任
我的建议:
- 日常写作用 Sonnet 4 就够了,性价比无敌
- 重要文档或者对文字质量要求极高的场合,可以考虑 Opus 4
想自己测试?推荐个神器 🛠️
这次评测我用的是 16x Eval 这个桌面工具,真的很好用!
你可以:
- 复制我的测试案例
- 设计自己的评测场景
- 对比不同模型的表现
- 找到最适合你需求的 AI 助手
强烈推荐给想要深入了解 AI 模型性能的朋友们。
最后的话 🎯
一周的深度测试下来,我对 Claude 4 的整体印象是:名副其实。
Anthropic 这次没有夸大宣传,Claude 4 确实在编程和写作两个领域都达到了新的高度。特别是代码的简洁性和创新思维,让我这个老程序员都眼前一亮。
我的推荐:
👥 普通用户:闭眼选 Sonnet 4,性价比无敌 💼 专业用户:预算充足就上 Opus 4,追求极致体验 🎓 学习者:Sonnet 4 是最好的编程学习伙伴 ✍️ 创作者:两个模型都很棒,按预算�选择即可
AI 发展到今天,我们已经不需要问"AI 能不能帮我写代码",而是要问"哪个 AI 能帮我写得更好"。
Claude 4 给出了一个很好的答案。
你们觉得呢?欢迎在评论区分享你们的使用体验!
本文所有测试数据均基于真实评测,评分标准包括正确性、完整性、代码质量、创新性等多个维度。如果你也想进行类似的评测,可以参考我们的开源测试数据。
关注我,获取更多 AI 工具评测和使用技巧! 🚀